실루엣 계수(Silhouette Coefficient) :
각 데이터 포인트와 주위 데이터 포인트들과의 거리 계산을 통해 값을 구하며,
군집 안에 있는 데이터들은 잘 모여있는지, 군집끼리는 서로 잘 구분되는지 클러스터링을 평가하는 척도로 활용된다.
* 참고한 논문의 표현을 빌리자면, 군집 내 비유사성('within' dissimilarities)은 작고, 군집 간 비유사성('between' dissimilarities)은 커야 생성된 클러스터의 품질이 좋다고 할 수 있다.
이번 포스팅에서는 실루엣 계수를 구하는 방법과 평가 지표로써의 장단점에 대해 알아보고자 한다.
실루엣 계수 구하는 방법


왼쪽 그림처럼 어떠한 클러스터링 기법에 의해 총 10개의 데이터 포인트들이 3개의 군집으로 나눠졌다고 하자.
클러스터 A의 데이터 포인트 i를 선택하고, 데이터 포인트 i의 실루엣 계수를 구할 것이다.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -


우선 데이터 포인트 i가 속한 클러스터 A 안에 있는 다른 데이터 포인트들과의 거리 평균을 구한다.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
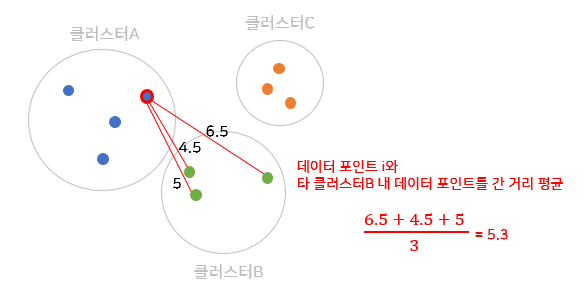


그리고, 데이터 포인트 i가 속하지 않은 클러스터 B의 데이터 포인트들과 거리 평균을 구하고, 마찬가지로 클러스터 C의 데이터 포인트들과 거리 평균을 구한다.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -

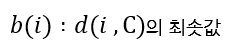
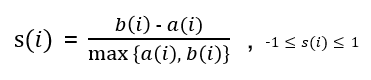
클러스터 B와 C 중 데이터 포인트 i와 가까운 클러스터(=이웃 클러스터)는 B이므로 \(b(i)\) 값은 5.3이 되며, \(a(i)\), \(b(i)\) 값으로 데이터 포인트 i의 실루엣 계수 \(s(i)\) 값을 구한다.
* 실루엣 계수 계산식의 분모는 두 군집 간 거리를 정규화하는 스케일러의 역할을 한다.
* 동일한 클러스터 내에 있더라도 데이터 포인트마다 이웃 클러스터는 다를 수 있다.
* 만일 클러스터 안에 1개의 데이터 포인트만 존재하는 경우, 해당 데이터 포인트의 실루엣 계수는 0으로 본다.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -

위 그림처럼 모든 데이터 포인트들에 대해 실루엣 계수를 계산했다면, 실루엣 계수들의 평균값(overall average silhouette width)을 계산해준다. 만일 클러스터 개수별로 여러 번 군집화를 수행했거나, 여러 클러스터링 기법으로 여러 번 군집화를 수행한 경우 실루엣 계수의 평균값을 비교하여, 클러스터 개수를 몇 개로 할 것인지, 혹은 어떤 클러스터 기법을 선택할 것인지 판단할 수 있다.
* 실루엣 계수의 평균값이 1에 가까울수록 군집화가 잘 되었다고 생각할 수 있다.
* 각 클러스터 내의 데이터 포인트들의 실루엣 계수 평균값을 구하여, 각 클러스터별 평균값도 구할 수 있다. 1에 가까운 평균값을 가지는 클러스터는 'clear-cut' 클러스터, 0에 가까운 값을 가지는 클러스터는 'weak' 클러스터로 표현된다.
추가적으로 실루엣 계수에 대해 조금 더 살펴보면,
- \(s(i)\)가 0에 가까운 경우는, 두 군집 간 거리가 거의 비슷한 경우를 의미하며 잘 구분되지 않은 상태이다.
- \(s(i)\)가 -1에 가까운 경우는, 데이터 포인트 i가 오히려 이웃 클러스터에 더 가까운 경우를 의미하며 아예 잘못 할당된 상태라고 볼 수 있다. 그래서 이러한 경우는 실제로는 거의 나타나지 않는다.
실루엣 분석의 장점
- 클러스터링이 수행된 후 실제 구분된 클러스터에 따라 실루엣 계수를 구하기 때문에, 클러스터링 알고리즘에 영향을 받지 않는다.
- 적절한 클러스터 개수를 정하거나 더 나은 클러스터링 기법을 선택하는 기준으로 삼을 수 있다.
- 클러스터링 결과 값을 시각화할 수 있다.
실루엣 분석의 단점
- 데이터 양이 많아질수록 수행 시간이 오래 걸린다.
*만일 100개의 데이터 포인트가 있다면 99개의 다른 데이터 포인트들과 거리를 구해 실루엣 계수를 구해야 하고, 이런 동일한 연산을 100번 수행해야 한다. - 전체 데이터 포인트의 실루엣 계수 평균값만으로 클러스터링 결과를 판단할 수 없으며 개별 클러스터의 평균값도 함께 고려해야 한다.
참고자료
- 파이썬 머신러닝 완벽 가이드(권철민 저) 인프런 온라인 강의
- Peter J.Rousseeuw (1987), Silhouettes: a graphical aid to the interpretation and validation of cluster analysis , Computational and Applied Mathematics 20: 53-65
다음 포스팅에서는 실루엣 계수를 어떻게 시각화하여 분석에 활용하는지 python 코드와 함께 알아볼 것이다. 👀
'머신러닝' 카테고리의 다른 글
| [머신러닝] GMM(Gaussian Mixture Model) 군집화 (3) | 2021.08.19 |
|---|---|
| [머신러닝] 클러스터링 평가지표 - 실루엣 계수(2) (0) | 2021.07.21 |
| [머신러닝] K-Means 군집화 (4) | 2021.05.30 |
| [머신러닝] S.O.M 알고리즘 (2) - MiniSom (3) | 2021.05.12 |
| [머신러닝] S.O.M 알고리즘 (1) - 개념 (0) | 2021.05.04 |




댓글