본 포스팅은 고려대학교 산업경영공학부 강필성 교수님의 [Korea University] Business Analytics (Graduate, IME654) 강의 중 04-9: Ensemble Learning - CatBoost 영상을 보고 정리한 내용입니다.
0. GBM 요약
- 순차적으로 모형을 만들어 감, t 번째 부스팅 모형은 t-1까지 누적된 부스팅 모형에, 현재 t 시점에서의 모형 \(h^t\)에 가중치 \(\alpha\)를 곱하여 더하여 도출

- \(h^t\)는 정답값과 추정 값에 대하여 expectation loss를 최소화 하는 함수 h를 의미

- \(h^t\)는 loss functiond의 -gradient, \(-g^t(x,y)\)로 근사 가능

- least squares approximation을 사용할 때의 \(h^t\) 도출 과정

1. CatBoost Background - Gradient Boosting의 한계
1) Target Leakage : target value가 feature value를 계산하는데 사용되어 target(정답) 정보가 새는 문제 발생
- Target Statistic(TS) : training dataset에서 categorical feature를 target value의 평균 값으로 대체하여 numerical feature로 변환하는 방법
- test dataset에서는 training dataset과 다르게 \(x_i\)의 target value를 사용하지 않으며, 이로 인하여 conditional shift 발생
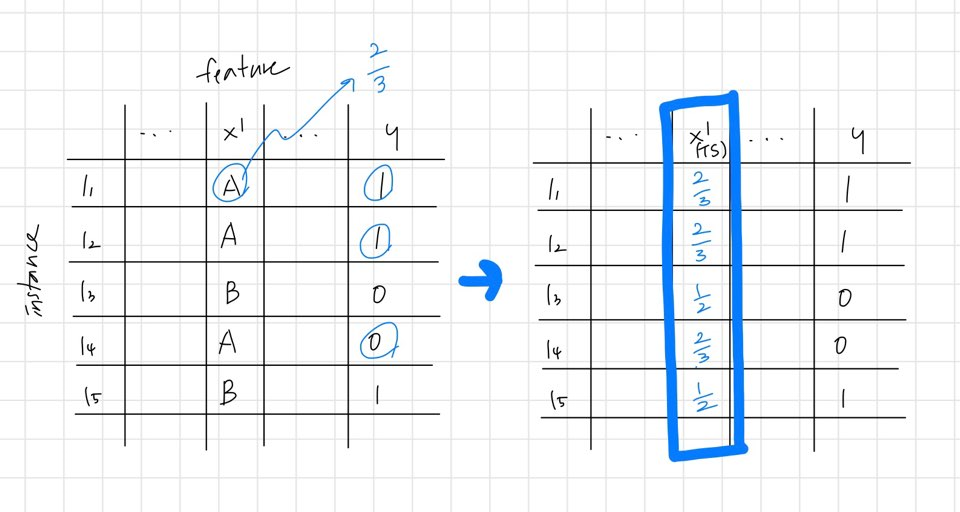
2) Prediction Shift : loss function에 대한 expectation 값을 구해야 하는데, 유한한 데이터인 training data 뿐이기 때문에, \(\frac{1}{n}\sum\)으로 근사하여 계산할 때 발생하는 문제
- training example \(x_k\)가 주어졌을 때, 누적된 부스팅의 F 함수 값 \(F^{t-1}(x_k)\)와, test example x가 주어졌을 때, \(F^{t-1}(x)\) 값이 달라서 모델링에 대한 정합성이 확보되지 않음

2. CatBoost Idea
1) Target Leakage 이슈 > Ordered Target Statistics 도입
2) Prediction Shift 이슈 > Ordered Boosting 도입
3. Categorical features in boosted tree
- one-hot encoding : 기본적인 방법, category의 종류가 증가함에 따라 변수의 수가 증가하고, 계산 상 비효율적인 부분이 발생함
- Greedy TS : 자주 사용되는 방법, 동일한 category를 그룹핑하여, target value의 평균값으로 대체, 앞서 1-1) 예시 참고
- Greedy TS with smoothing : 빈도 수가 적은(noise와 같은) category의 Greedy TS 값이 너무 극단적으로 나오는 것을 방지하기 위한 방법론
+ a : 0보다 큰 hyper parameter
+ p : 전체 dataset에 대한 target value 평균


- Greedy TS를 적용하면 아래와 같이 극단적인 상황에서는 구분 능력이 아예 없어짐

4. Categorical features in boosted tree in CatBoost to prevent Target Leakage
1) Property 1 : TS는 training 데이터와 test 데이터의 expectation이 같아야 함

2) Property 2 : 가급적이면 TS를 계산하기 위해 모든 training 데이터를 효과적으로 사용하도록 함
Idea 1) \(x_k\)를 제외한 dataset \(D_k\)를 구성하고, \(D_k\)로 TS를 계산 - 한계점 있음
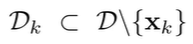

- Holdout TS : dataset을 2개로 구분해서 하나는 TS 계산에만 사용하고, 하나는 training에만 사용함, TS를 사용하기 위해 가급적 모든 데이터를 사용하기로 한 Property 2 위반
- Leave-one-out TS : training에는 \(x_k\)를 제외한 \(D_k\)를 사용하고, test 때는 D 사용함 - target leakage를 방지할 수 없음
Idea 2) training dataset에 가상의 시간 개념(artificial time)을 도입하여 계산
- Ordered TS : 객체들을 랜덤하게 섞어준 후 (permutation), 이전 시간의 객체들에 대해서만 TS를 계산
+ TS 계산이 permutation에 큰 영향을 받기 때문에, permutation을 자주 수행함
+ TS 계산 중에 target value도 사용하지 않고, 전반적인 데이터를 모두 사용하는 방법!



5. to prevent Prediction Shift in CatBoost
Idea ) I개의 tree를 가지고 있는 모형을 만들 때, \(F^{I-1}\)까지의 모델은, \(x_k\)없이 학습되어야 함
- Ordered Boosting : 객체들을 랜덤하게 섞어준 후 (permutation), 잔차 계산 시 이전 객체들만 사용하여 학습
- 첫 번째 객체만을 이용해서 tree를 생성한 후, 두 번째 객체와 잔차를 계산
- TS computing과 ordered boosting에서 동일한 permutation 사용됨

6. CatBoost 수행 단계
1) 초기화 : training dataset으로부터 s+1개의 independent random permutation을 생성
- s permutations to evaluate the split
- 1 permutation to compute the leaf value of the obtained trees
+ 1개의 permutation만 사용하면 최종 모델 예측 값의 variance가 매우 커질 것
2) (oblivious tree를 기반으로) supporting model \(M_{rj}\) 생성 : permutation이 r일 때, 이전 j 번째 객체들로만 M을 생성하고, TS도 계산됨, i 번째에 대하여 잔차를 계산함, \(y_i - M_i(x_i)\)
3) gradient를 계산한 후에, candidate split에 대하여 loss function 계산, split evaluation step에서, 이전까지 만들어진 gradient를 평균 내서 leaf value인 \(\triangle(i)\)를 계산함
참고 자료
'머신러닝' 카테고리의 다른 글
| [분석 방법론] Semi supervised Learning(2) - Self-Training & Co-Training (0) | 2023.01.12 |
|---|---|
| [분석 방법론] Semi supervised Learning(1) - Overview (0) | 2023.01.06 |
| [분석 방법론] Ensemble Learning(8) - LightGBM (0) | 2023.01.01 |
| [분석 방법론] Ensemble Learning(6) - Gradient Boosting Machine(GBM) (0) | 2022.12.28 |
| [분석 방법론] Ensemble Learning(7) - XGBoost (0) | 2022.12.28 |




댓글