본 포스팅은 고려대학교 산업경영공학부 강필성 교수님의 [Korea University] Business Analytics (Graduate, IME654) 강의 중 04-5: Ensemble Learning - Adaptive Boosting(AdaBoost) 영상을 보고 정리한 내용입니다.
1. AdaBoost Idea
- random guessing보다 약간 더 잘하는 week model에 대하여, 앞선 모델이 잘 풀지 못했던 어려운 case에 가중치를 부여해서(reweight) 결국에는 strong model을 만들고자 함
- 모델 학습은 순차적으로 진행
- 분류 모델이라면 오분류된 example, 회귀 모델이라면 오차가 큰 example 을 찾아서, 새로운 training set에서 해당 example이 더 많이 나올 수 있도록 가중치를 부여함
- 앞선 모델에서 error가 컸던 example은 이어서 학습하는 모델에 대해서는 error가 작게 나올 것
- 테스트 데이터에 대해서는 각각 모델에서 도출된 결과를 집약해서 예측
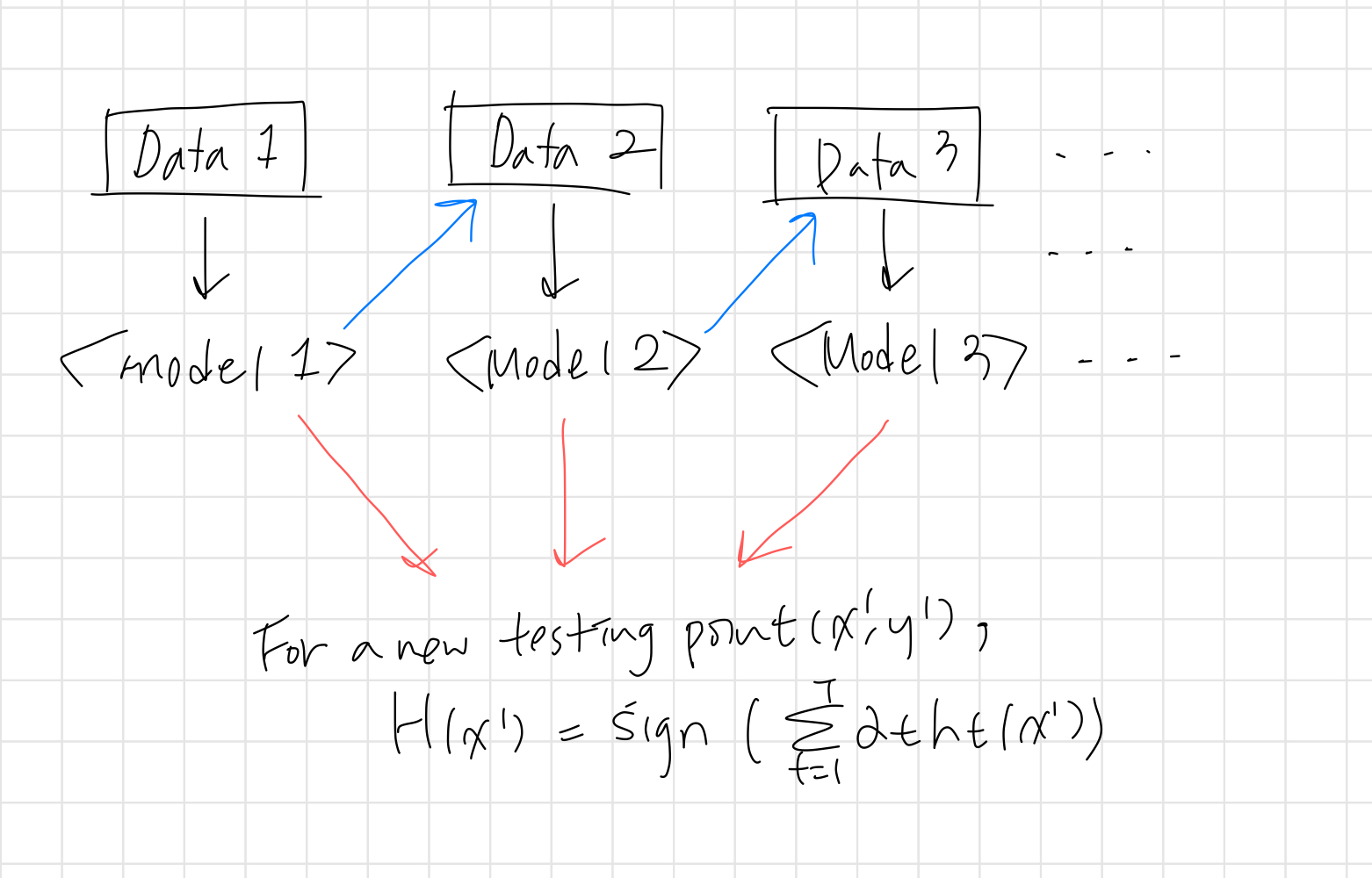
2. AdaBoost 알고리즘
- T : individual learner의 개수, 보통 50~100개 이상 사용
- \(D_1(i)\) : 첫 번째 dataset에서 데이터 포인트 i가 선택될 확률, 첫 번째여서 모든 i는 동등한 확률을 갖는다.
- \(h_t\) : 한 번만 split하는 stump tree를 주로 사용함
- \(\alpha_t\) : 모델이 정확할수록 커짐, 데이터 포인트의 가중치를 계산할 때, 최종적으로 예측할 때 반영되는 값
- \(D_{t+1}(i)\) : t+1 번째 dataset에서 데이터 포인트 i가 선택될 확률, 이전 학습 결과로 업데이트 됨
* bagging에서는 항상 동등한 확률을 갖는 example을 복원 추출, boosting에서는 example마다 뽑힐 확률이 달라진 상태에서 복원 추출

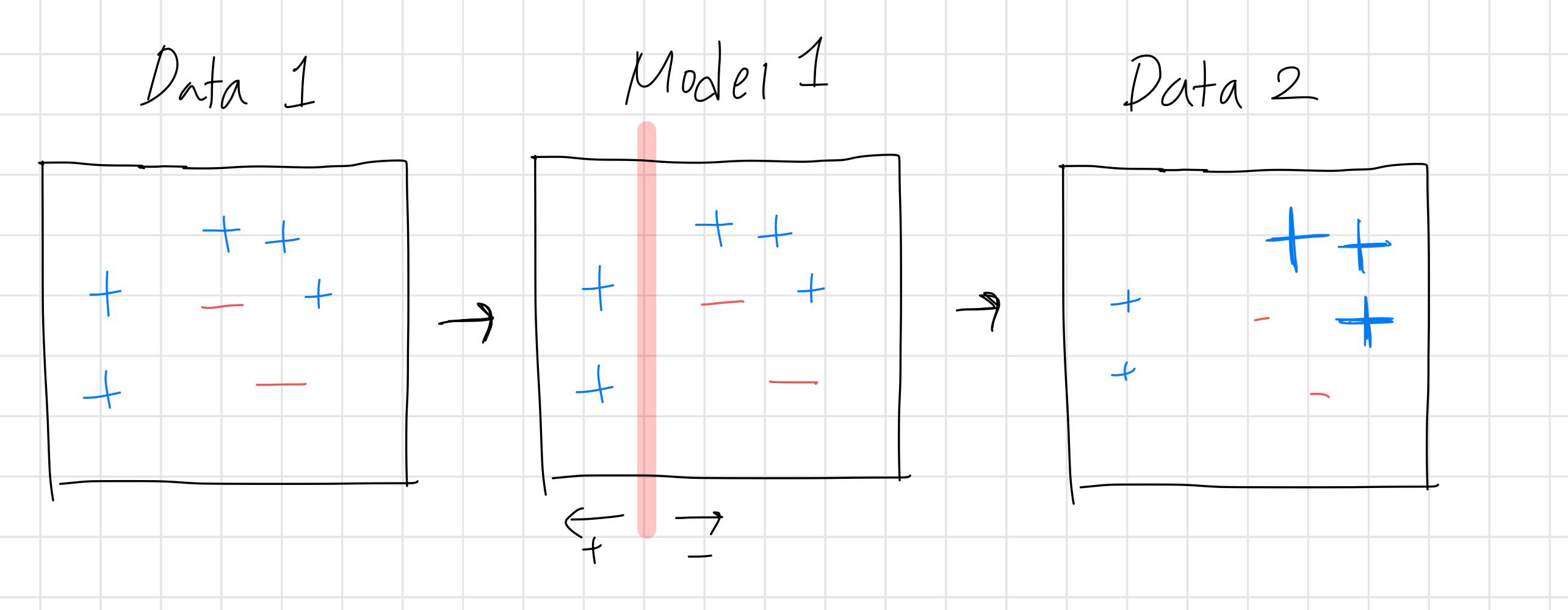
3. 샘플링 가중치 업데이트 예시
- \(D_{t+1}(i)\) : t+1 번째 dataset에서 데이터 포인트 i가 선택될 확률
- 1번 케이스 : 정답을 맞춰서 \(y_ih_t(x_i)\) =1, -\(\alpha_ty_ih_t(x_i)\) <0 👉 확률 감소
- 2번 케이스 : 정답을 맞춰서 \(y_ih_t(x_i)\) =1, -\(\alpha_ty_ih_t(x_i)\) <0 👉 확률 감소
- 3번 케이스 : 정답을 틀려서 \(y_ih_t(x_i)\) =-1, -\(\alpha_ty_ih_t(x_i)\) >0 👉 확률 증가

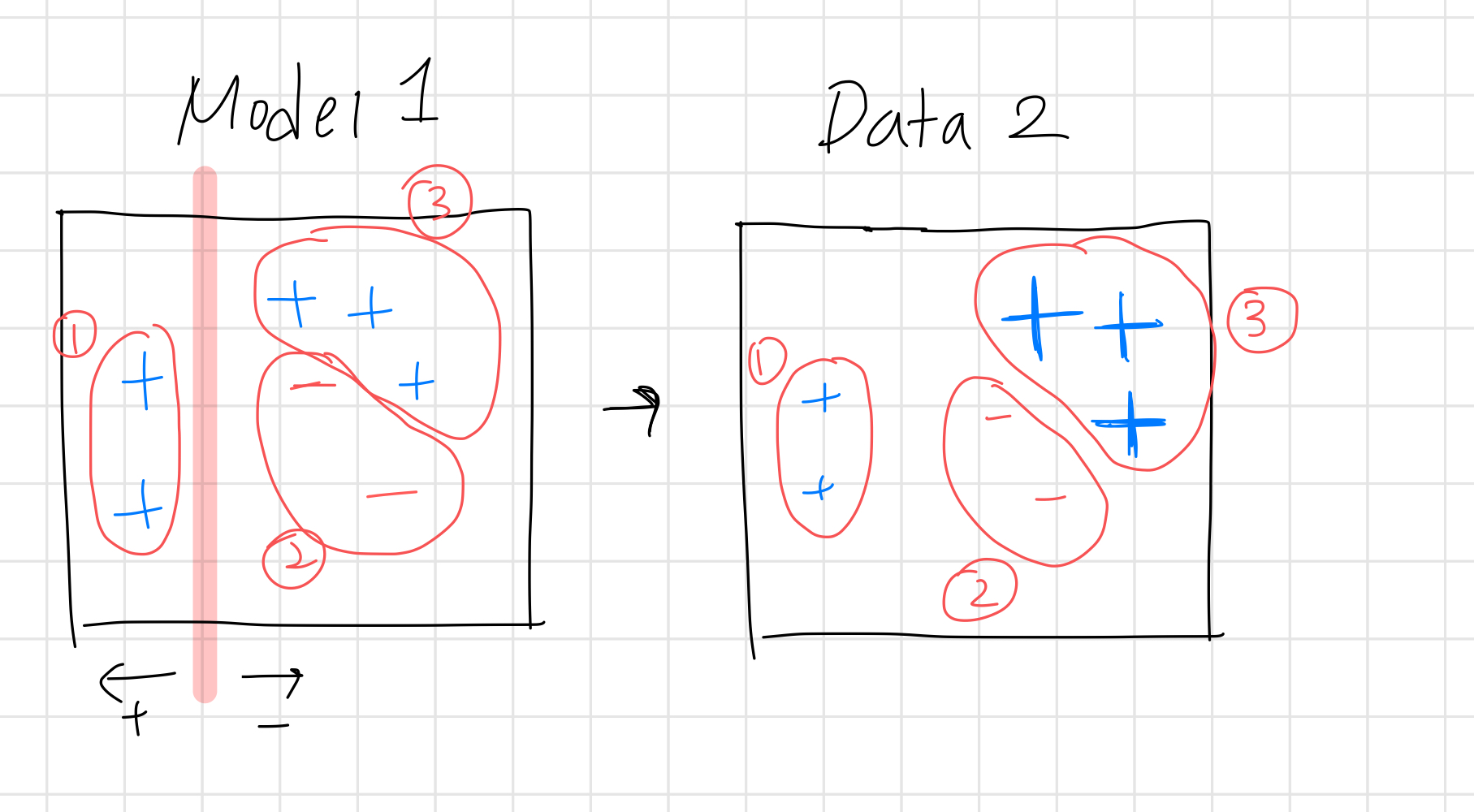
4. AdaBoost 예시

참고 자료
- https://www.slideshare.net/DataRobot/gradient-boosted-regression-trees-in-scikitlearn
'머신러닝' 카테고리의 다른 글
| [분석 방법론] Ensemble Learning(6) - Gradient Boosting Machine(GBM) (0) | 2022.12.28 |
|---|---|
| [분석 방법론] Ensemble Learning(7) - XGBoost (0) | 2022.12.28 |
| [분석 방법론] Ensemble Learning(4) - Random Forests (0) | 2022.12.12 |
| [분석 방법론] Ensemble Learning(3) - Bagging (0) | 2022.11.29 |
| [분석 방법론] Ensemble Learning(2) - Bias-Variance Decomposition (0) | 2022.11.29 |




댓글