본 포스팅은 고려대학교 산업경영공학부 강필성 교수님의 [Korea University] Business Analytics (Graduate, IME654) 강의 중 03-7: Anomaly Detection - Isolation Forest 영상을 보고 정리한 내용입니다.
1. Isolation Forest 개요
- 기본 가정 : abnormal 데이터는 normal 데이터보다 훨씬 적을 것이고, 매우 다른 속성을 가지고 있을 것
- 방법 : tree를 만들어서 데이터를 Isolate(고립) 시켜봄
+ abnormal 데이터는 적은 split으로도 고립시킬 수 있음
+ normal 데이터는 밀집되어 있기 때문에 훨씬 많은 split이 수행되어야 함
- 특징 : 임의의 변수를 선택하고, 임의의 데이터 포인트로 split을 진행

충분한 수의 트리를 만들면
2. 종료 조건
- 원래는 split한 영역에 target 데이터 포인트가 남을 때까지 split을 진행해야 하지만, 만약 우연히 모든 설명 변수에 대해 완전히 동일한 값을 가지고 있다면 중단
- hyper-parameter인 height limit을 미리 정의해두고, 해당 depth에 도달하면 split 횟수에 depth 값을 부여하고 중단
3. Path Length 개념
- path length h(x)는 데이터 포인트 x가 root 노드로부터 terminal node까지 도달하기 위한 edge의 수 (=split 횟수)
- 오일러 상수를 이용해서 평균적인 path length로 normalize 할 수 있음
* Euler's constant : H(i) = ln(i) + 0.5772156649
4. Novelty score (이상치 점수) 계산 방식
- 데이터 포인트 x의 novelty score s 는 path length와 average path length를 이용해서 아래와 같이 계산할 수 있음
- h(x) : 1개의 tree에서 x를 isolation 시키기 위한 split 횟수
- c(n) : n개의 데이터 포인트가 주어졌을 때, h(x)의 평균값, h(x)를 normalize하기 위한 값
5. Isolation Forest 알고리즘 학습을 위한 pseudo-code
- isolation을 하기 위한 target 데이터 포인트를 제외한 나머지 객체들은 sampling해도 무방
- 보통 258개 정도 sampling하여 활용하며, tree를 만들 때마다 sampling하기 때문에, 전체 데이터로 학습했을 때와 유사하게 학습됨
6. Isolation Forest 성능
- computational complexity 관점에서 ORCA, SVM, LOF, RF 등의 알고리즘보다 뛰어남
7. Extended Isolation Forest 개념
- Standard Isolation Forest는 수직과 수평으로 영역을 구분하고 있으며, 이로 인해 이상치 영역으로 판단되어야 하는 부분이 정상 영역으로 판단될 위험이 있음
- 이러한 한계를 극복하기 위해 영역을 구분하는 branch cut에 random한 slop(기울기)를 부여함
- Standard Isolation Forest 예시 :
+ 아래 그림에서 실제 데이터가 모여 있는 영역 외에 이상치 영역이 정상 영역과 유사하게 표현되고 있음
- Extended Isolation Forest 예시 :
+ 랜덤한 slope를 통해 영역을 split
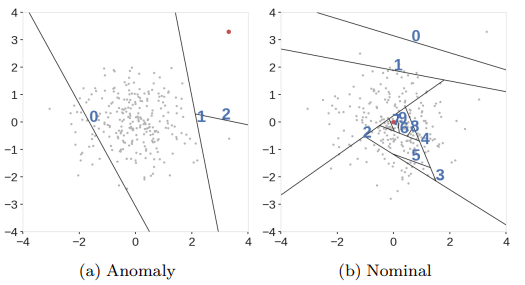
- Standard Isolation Forest와 Extended Isolation Forest 비교 :



참고 자료
- Liu, F.T., Ting, K. M., & Zhou, Z. H. (2008, December). Isolation forest. In Data Mining, 2008. ICDM'08. Eightn IEEE International Conference on (pp. 413-422).IEEE.
- Hariri, S., Kind, M. C., & Brunner, R.J. (2018). Extended Isolation Forest. arXiv preprint arXiv:1911.02141.
'머신러닝' 카테고리의 다른 글
| [분석 방법론] Ensemble Learning(2) - Bias-Variance Decomposition (0) | 2022.11.29 |
|---|---|
| [분석 방법론] Ensemble Learning(1) - Overview (0) | 2022.11.23 |
| [머신러닝] GMM(Gaussian Mixture Model) 군집화 (3) | 2021.08.19 |
| [머신러닝] 클러스터링 평가지표 - 실루엣 계수(2) (0) | 2021.07.21 |
| [머신러닝] 클러스터링 평가지표 - 실루엣 계수 (1) (3) | 2021.06.15 |




댓글