[Coursera] Convolutional Neural Networks 4주차 강의 (Special Applications: Face Recognition & Neural Style Transfer)를 수강하며 작성한 필기 노트입니다.


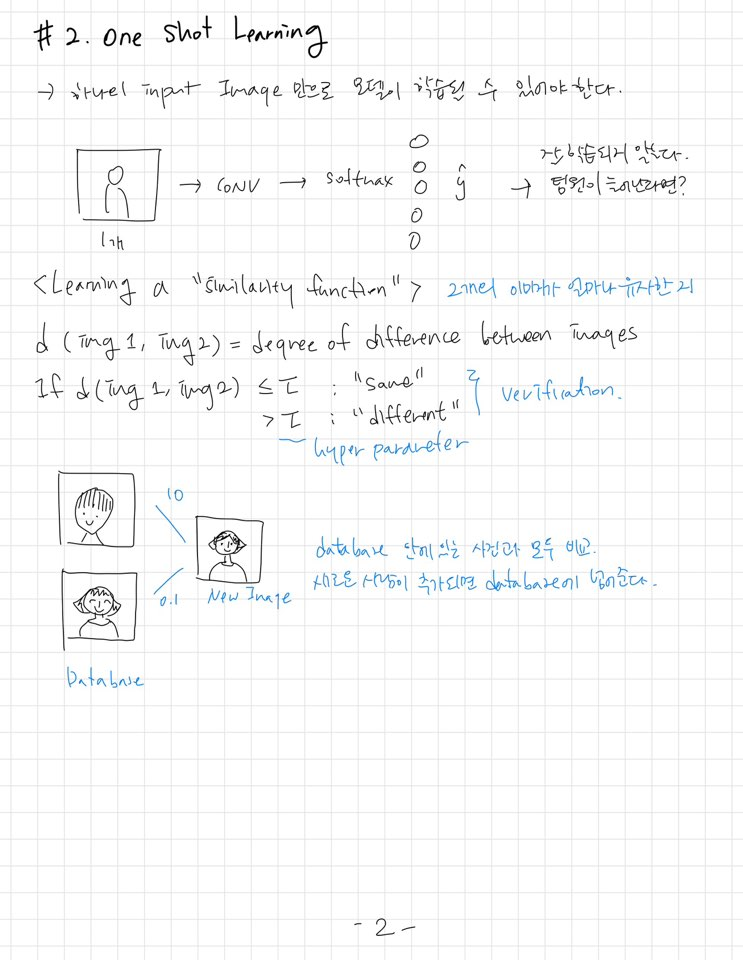
1-2 강의에서 face recognition 문제를 풀기 위해서는 'one-shot learning' 가능해야 한다고 했다. 그런데 뒤에 나오는 'triplet loss'에서는 모델 학습에 한 사람당 여러 장의 이미지가 필요하다고 해서, 의문이다. 모델 학습 시에는 여러 장이 필요하고, 모델이 학습된 이후에 새로운 사람을 recognition할 때에는 1장의 이미지만 필요하다는 의미일까? 아니면 최소한의 이미자만으로 모델 학습이 진행되어야 한다는 의미였을까? 아직 헷갈린다.


hyper-parameter인 \(\alpha\)가 있는 이유는, \(f(A)\), \(f(P)\), \(f(N)\)이 0을 뱉어서 수식이 만족될 수도 있기 때문이다. 또한 좋은 A, P, N 쌍을 선택하려면, 랜덤하게 하는 것보다는, A와 N이 비슷해서 판단하기 "어려운" 셋을 골라야 성능이 좋은 모델을 학습할 수 있다.






l 번째 layer에 대해서 (채널 수 x 채널 수) shape을 갖는 2차원의 style matrix가 생성된다. 그리고 style 이미지와 generate된 이미지의 style matrix의 차이를 cost로 본다.





댓글